Extended Context. Agents also need to take notes
Published on 🤖 If you want your AI to read this post, download it as markdown.
The purpose of this post is to describe a context expansion strategy in the development of complex projects with agents. But since not only LLMs need context to understand ideas, I'll start with a bit of context for humans.
If you're in a hurry and want to skip the previous context, go ahead and don't worry, no one will know you had this mini laziness attack 😬
Context for humans
The emergence of agents in code assistants has represented a huge leap in AI-assisted software development.
The first striking feature is their ability to automatically iterate on their own responses, create/modify files, and run commands in the terminal. But I think the skill that really makes a difference is their ability to index and analyze a project's code, including dependencies between files and relationships between its components.
If assistants allowed us to work at the file level, with the appearance of agents we have moved to working at the architecture level. Now AI not only helps us in writing/fixing parts of our code, but also assists us in building complete projects (at a speed that sometimes makes you dizzy).
But this increase in the complexity of the tasks developed causes something that was difficult to see before - we push the context window of the agents themselves to the limit. Developing a complete project requires many tasks, so at some point in the conversation the agent begins to forget parts of the conversation, making it very difficult (if not impossible) to maintain the coherence of the work we are doing.
When this happens, the most common approach is to open a new chat to reset the context window, but how do we bring the agent to the point where we were? How do we make it remember what it had already built and what it still needs to develop?
In my case, I'm using a strategy that I've been defining from my interactions with Cursor first and GitHub Copilot Agent Mode afterwards, which I call Extended Context. I know I'm not very original, but I think it expresses the idea decently 🤓
Extended context (using markdowns as memory)
This strategy is based on storing markdown files with project information in a folder called context/
The central idea is to create a memory that the agent (or we) can access at any time, allowing it to know what point it's at and what remains to be done
Thanks to this memory, we can divide the work into small tasks and use as many chats as necessary to avoid reaching the context window limit. This way, we maintain the coherence and quality of the work from start to finish.
Working scheme
The working scheme is summarized in the following image.
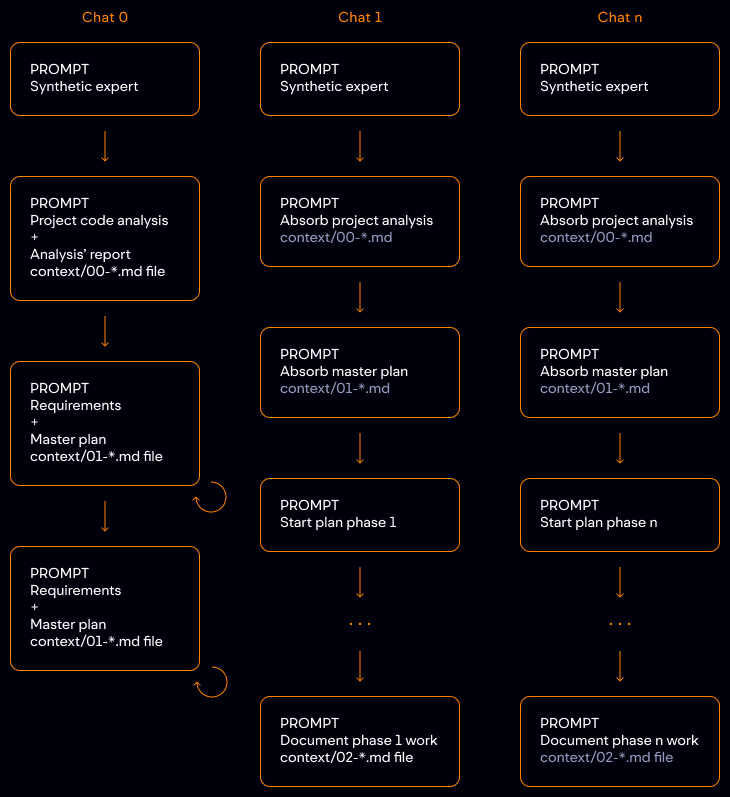
Chat 0
- Prompt to create a synthetic expert in the project's technology: role, experience, technical stack, reasoning approach, and response format. Ending with a "don't write code yet".
- Prompt where we ask it to:
- analyze the project code,
- generate a report of its analysis,
- and save it in
.mdformat inside thecontext/folder with a 00- prefix in the filename. If we are not completely satisfied with the report, we can iterate on it until we are satisfied.
- Prompt where:
- we indicate what we want to do (requirements),
- ask it to generate a master plan,
- and save the master plan in
.mdformat inside thecontext/folder with a 01- prefix in the filename. As with the analysis, we can iterate on it until we are satisfied.
Chat 1
- Same prompt for creating a synthetic expert.
- Prompt asking it to read and internalize the project analysis.
- Prompt asking it to read and internalize the master plan.
- Prompt asking it to execute point 1 of the master plan.
- Normal iteration until point 1 is completed.
- Prompt asking it to document the work developed in point 1 in a
.mdfile insidecontext/following the current numbering and to mark the point as resolved in the master plan.
Chat n
- Same prompt for creating a synthetic expert
- Prompt asking it to read and internalize the project analysis
- Prompt asking it to read and internalize the master plan
- Prompt asking it to execute point n of the master plan
- Normal iteration until point n is completed.
- Prompt asking it to document the work developed in point n in the previously created documentation
.mdfile and to mark the point as resolved in the master plan.
Obviously, this scheme is a working base that can be modified according to the needs of each project and that I hope to improve over time. Even so, in its initial form, I think it already offers some advantages compared to not using any strategy.
Advantages of extended context
- We avoid context loss: the agent can consult the files when it needs to remember where it came from and where it's going.
- Continuity: we can close the computer and resume work days later without losing the thread.
- Collaboration: other team members can easily understand the project's status and continue it (with their agents).
- Automatic documentation: upon completion, we already have structured documentation.
- Facilitates task division: orienting work towards agile methodologies and sprints.
Finishing up
It's ironic that in this imitation of human thinking represented by language models, we have not only copied their capabilities but also their limitations. And among them is a very human one: forgetting. So just like imperfect humans, imperfect LLMs also need to take notes. That said, if they're in markdown, even better - they love markdown!
By the way, do you have your agents take notes or do you have any other strategy when developing complex projects? If you work differently, I'd love to hear about your experience 😊